
Large Language Models (LLMs) are incredibly powerful, but they have a massive blind spot: their knowledge is only as good as their last update. An LLM only knows what it learned from its training data, which means it is completely in the dark about recent events, your company’s internal documents, or anything else that happened after it was trained.
This is exactly why AI models sometimes “hallucinate” and confidently make things up because they just don’t know the real answer. It’s a huge problem, especially for businesses where accuracy is everything.
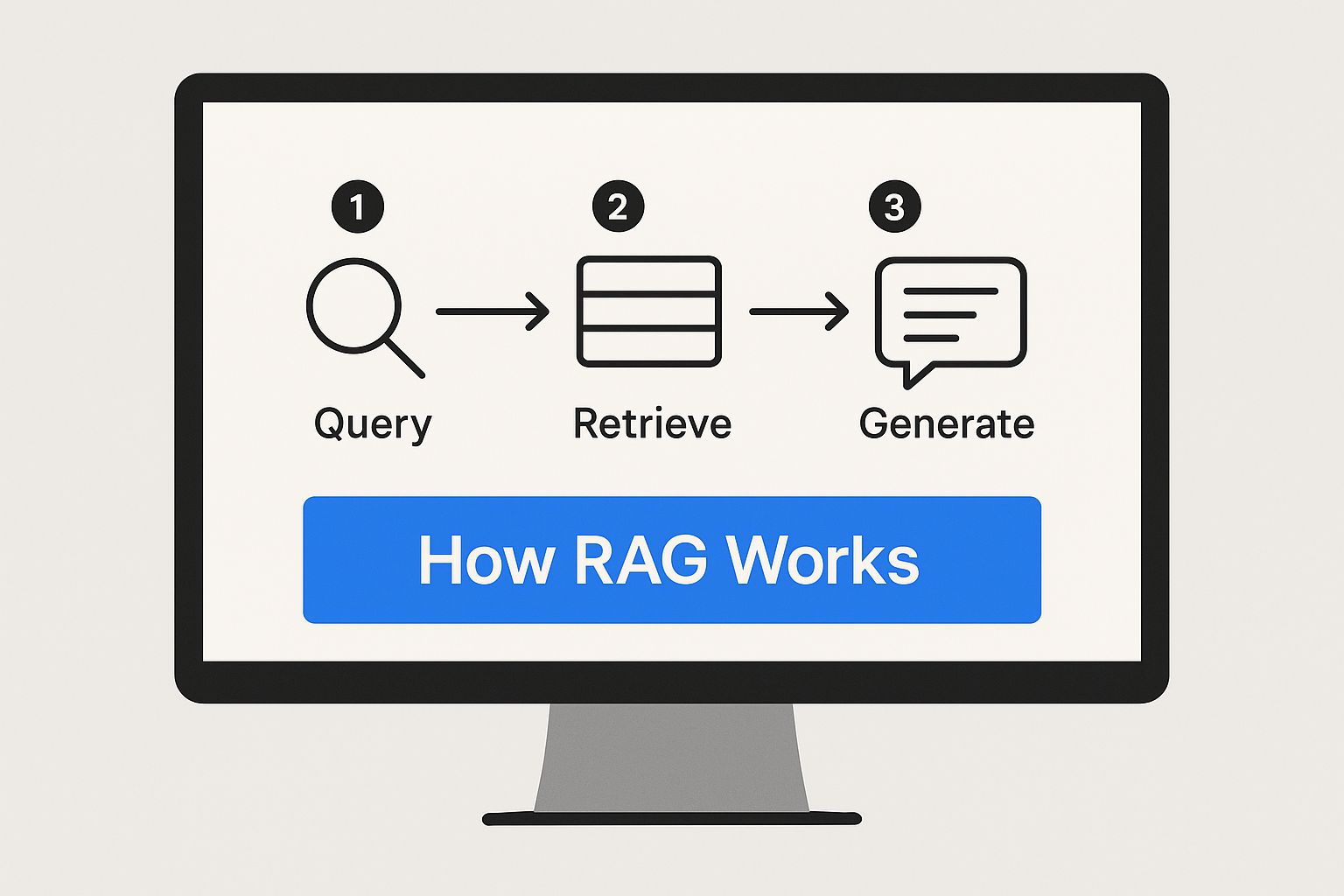
So, What Is Retrieval-Augmented Generation (RAG)?
This is where Retrieval-Augmented Generation, or RAG, comes in. It’s a surprisingly straightforward way to solve the LLM’s knowledge gap problem.
Instead of just relying on its static, internal knowledge, a RAG-powered model can “look up” relevant information from a trusted, external source first. This simple step grounds the AI’s response in verifiable facts, making it far more accurate and trustworthy.
The Problem RAG Solves
Without RAG, LLMs run into a few critical issues that make them unreliable for serious business applications.
- Outdated Information: A model trained in 2024 has zero knowledge of anything that happened in 2025. This makes it practically useless for tasks that need current information.
- Factual Inaccuracies (Hallucinations): When an LLM doesn’t know something, its instinct is to guess. RAG stops this by feeding it the actual facts, drastically cutting down on those made-up answers.
- Lack of Specificity: A general-purpose model knows a little about a lot, but it has no clue about your company’s internal knowledge base, support manuals, or specific product details.
By connecting the LLM to your own curated knowledge source, RAG patches all these weaknesses at once.
A RAG system works in two simple steps. First, it retrieves relevant information from your documents based on the user’s question. Then, it augments the prompt to the language model with that retrieved context, telling it to generate an answer based only on the facts provided.
This “retrieve-then-generate” process is what makes the whole system click. It allows you to build AI chatbots and assistants that are grounded in your own proprietary data, making every response relevant, accurate, and current.
Best of all, you don’t have to go through the incredibly expensive and time-consuming process of retraining the model every time you have new information. You just update your knowledge base. The end result is a smarter, more capable AI that your team and your customers can actually trust.
How the RAG Architecture Actually Works
To really get what makes Retrieval-Augmented Generation (RAG) so powerful, it helps to peek under the hood. The whole system runs on a simple but smart two-step process: first, it finds the right information, and second, it uses that information to put together a smart answer. This is what turns a generic LLM into a focused, subject-matter expert for your business.
It all kicks off the second a user asks a question. Instead of tossing that query straight to the LLM, the RAG system catches it and starts the first phase: retrieval. This is all about gathering the puzzle pieces needed to build an accurate, relevant response.
Phase 1: The Retrieval Process
The first hurdle is getting a machine to understand human language well enough to search with it. RAG handles this by converting the user’s query into a special numerical format called an embedding. You can think of this embedding as a unique digital fingerprint or a coordinate that captures the actual meaning behind the question.
Once the query has its numerical fingerprint, the system goes into a specialized knowledge base called a vector database. This isn’t your average database; it’s filled with pre-processed chunks of your own documents, and each piece has also been converted into an embedding. The system then runs a similarity search, hunting for the document chunks whose embeddings are the closest mathematical match to the query’s embedding.
In short, this phase isn’t searching for keywords. It’s searching for contextual meaning. The goal is to find the snippets of text from your knowledge base that are most conceptually similar to the user’s original question.
Let’s say a customer asks a support chatbot, “What is your policy for returning a product after 30 days?” The RAG system turns this question into an embedding and scans its vector database, which holds all of the company’s support articles. It quickly pinpoints the most relevant document, the official return policy, and pulls out the specific paragraphs that talk about returns outside the normal window.
This focused search-and-retrieve mission makes sure the LLM has the exact, relevant facts on hand before it even starts to formulate an answer. This data-driven foundation is what really sets a RAG system apart.
Phase 2: The Generation Process
With the most relevant information now in hand, the system switches over to the generation phase. It takes the original user query and bundles it together with the factual snippets it just pulled from the vector database. This combined package is then passed to the LLM as an augmented prompt.
This new prompt is far more powerful than the original question alone. It’s effectively telling the LLM, “Here is a user’s question, and here are the precise facts from our own knowledge base that you must use to answer it.” The LLM’s job is no longer to guess or recall information from its massive, static training data. Its job is to synthesize a fresh answer based on the contextual, up-to-date information it was just given.
Picking up our example, the LLM receives the customer’s question about the 30-day return policy alongside the retrieved text. It then crafts a clear, accurate response, like, “According to our policy, returns after 30 days are eligible for store credit, provided the item is in its original condition.”
The whole process is incredibly methodical and grounded in facts, as you can see in this visualization of the RAG data pipeline.
This flowchart neatly illustrates how the system filters user queries through a proprietary knowledge base before generating a final, augmented response. This structured approach is gaining serious momentum, with the RAG market projected to explode from USD 1.96 billion in 2025 to USD 40.34 billion by 2035. You can find more details on these trends and the future of RAG in this market analysis report.
To put it all in perspective, here’s a simple comparison of how a standard LLM and a RAG-powered LLM stack up.
Standard LLM vs RAG-Powered LLM
| Feature | Standard LLM | RAG-Powered LLM |
|---|---|---|
| Knowledge Source | Relies on its massive, static training data. | Accesses a specific, up-to-date external knowledge base. |
| Information Freshness | Can be outdated; knows nothing after its last training date. | Always current, as the knowledge base can be updated anytime. |
| Response Accuracy | Prone to “hallucinations” or making up facts. | Grounded in factual, verifiable data from the knowledge base. |
| Source Citation | Cannot cite its sources or explain its reasoning. | Can point to the exact document used to generate the answer. |
| Customization | Very difficult and expensive to fine-tune with new data. | Easily customized by simply adding new documents to the database. |
As you can see, RAG doesn’t just make LLMs a little better. It fundamentally changes how they access and use information to give you answers you can actually trust.
What Are the Real-World Benefits of RAG?
Putting Retrieval Augmented Generation (RAG) to work offers some seriously practical advantages. It’s what turns AI conversations from interesting experiments into reliable, must-have business tools. RAG directly shores up the biggest weaknesses of standalone Large Language Models (LLMs), making them far more accurate, trustworthy, and genuinely useful for what your organization actually needs.
The most immediate win? A massive boost in accuracy and a steep drop in those weird AI “hallucinations.”
By grounding every single response in your own curated, external knowledge base, a RAG system basically forces the LLM to behave more like a diligent research assistant than a freewheeling creative writer. It finds verifiable facts first, then puts together an answer based on that solid information. This simple process dramatically cuts down the risk of the model just making up plausible-sounding but totally wrong details, a non-negotiable for any business where getting the facts right matters.
When an LLM uses RAG to generate an answer, that response is anchored to real data. This makes the output more reliable and builds a foundation of user trust because the system can actually show you where it got its information.
Gaining Real-Time Knowledge Without Constant Retraining
One of the most powerful things about RAG is its ability to tap into current information. Standard LLMs are basically frozen in time, with their knowledge stopping the day their training ended. RAG completely gets around this by connecting the model to a live, dynamic source of information.
This means you can keep your AI up-to-date on the latest product specs, policy changes, or market news just by updating a document in your knowledge base. You don’t have to go through the incredibly expensive and time-consuming process of fully retraining a foundational model, which can take weeks and burn through a staggering amount of computing power. For a financial firm that needs up-to-the-minute market analysis, this kind of agility is everything. In fact, many of the incredible benefits of AI in finance are only possible because of this ability to access real-time data.
This approach gives you two key advantages:
- Speed: Adding a new PDF or updating a web page in your knowledge base is almost instant. The RAG system can start pulling information from that new source right away.
- Efficiency: The cost and effort are just a tiny fraction of what it takes to retrain a model, making sophisticated, customized AI a realistic goal for a lot more organizations.
Improving Transparency and Building User Trust
Let’s be honest: trust is a major hurdle for getting AI adopted in a business setting. People need to feel confident that the information they’re getting is correct and, just as importantly, verifiable. RAG builds this trust by making the AI’s thought process transparent. Since the system has to retrieve specific documents to come up with an answer, it can also cite its sources.
Think about it. When an employee asks an internal HR chatbot a question about the company’s leave policy, a RAG-powered system can give them the answer and a direct link to the exact section of the HR manual it used. This kind of transparency is a game-changer. It lets users check the information for themselves, turning the AI from a mysterious black box into a dependable assistant.
This is especially huge for customer-facing tools. When you’re using chatbots for business, showing customers the “why” behind an answer can boost satisfaction and cut down on frustrated calls to human agents. To see how this works in practice, you can learn more about integrating AI-powered chatbots for business to create better customer interactions.
Achieving Cost-Effectiveness at Scale
While any new tech comes with a price tag, RAG is a remarkably cost-effective way to customize an LLM for your specific needs. The main alternative, fine-tuning, involves retraining parts of the model on a specialized dataset. It works, but it can be computationally brutal and get very expensive, very fast.
RAG provides a much more economical way to get that specialization. Your main investment is in building and maintaining a clean, well-organized knowledge base. The foundational LLM itself doesn’t change; it just acts as a reasoning engine that works with the information you feed it. This clean separation of knowledge and reasoning makes the whole system more modular, easier to scale, and a lot cheaper to maintain over the long haul.
Common Use Cases for RAG in Business
Technical architecture is one thing, but how Retrieval-Augmented Generation (RAG) solves actual business problems is what really matters. Its ability to connect a powerful language model to your own private, curated knowledge opens up a ton of practical applications.
Businesses are now using RAG to build smarter, more reliable AI tools that deliver immediate value. These are not basic chatbots anymore; we’re talking about sophisticated systems for managing internal knowledge, supercharging customer support, and even handling complex content creation.
Let’s look at a few common ways RAG is already being put to work.

Advanced Internal Knowledge Hubs
Most companies have enormous internal knowledge bases like wikis, policy manuals, technical specs, and project archives. The problem? Finding anything specific is a nightmare. A simple keyword search often spits back dozens of irrelevant documents, forcing your team to waste time digging for answers.
RAG completely changes this by turning these static repositories into interactive, conversational knowledge hubs.
- The Problem: A new software engineer needs to get up to speed on a poorly documented piece of a legacy codebase. Searching the internal wiki is slow and the results are often outdated.
- The RAG Solution: The company rolls out a RAG-powered Q&A system connected to all its technical documentation, code comments, and project histories. The engineer can now just ask a natural question like, “What’s the purpose of the authentication module in Project Phoenix, and how does it handle expired tokens?”
- The Outcome: The system instantly pulls the exact code snippets and design docs, synthesizing a clear explanation in seconds. This slashes onboarding time and frees up senior developers from answering the same questions over and over again.
This kind of application is poised to be a massive driver for RAG adoption. In fact, document retrieval is expected to dominate the market with a share of 65.8%, largely because of its role in pulling precise information from huge data repositories. Industries that depend on accurate documentation like legal, healthcare, and finance are contributing big time to this growth.
Smarter Customer Support Chatbots
We’ve all been there: stuck in a loop with a generic chatbot that only offers scripted, unhelpful answers. They often fail to grasp what you’re asking and just end up escalating simple issues to a human agent, which defeats the whole purpose. RAG gives chatbots the “brains” they need to provide precise, helpful answers based on actual product information.
By connecting a chatbot to a knowledge base of product manuals, FAQs, and troubleshooting guides, RAG allows it to function like a top-tier support agent with perfect product recall.
For instance, a customer can ask something super specific like, “How do I factory reset my Model X-2000 smart thermostat if the screen is frozen?” Instead of the classic “visit our support page” cop-out, a RAG-powered chatbot retrieves the exact reset sequence from the user manual and lays it out in clear, step-by-step instructions.
This is a huge leap forward for automated support. The system can handle a much wider range of complex questions, resolving issues faster and keeping customers happy. As we cover in our guide on using a chatbot in customer service, integrating this kind of AI can be a powerful strategy.
Automated Content Creation and Summarization
Creating detailed reports, summaries, and analyses often means pulling information from multiple sources. It’s a tedious manual process that’s just begging for human error. RAG automates a lot of this heavy lifting, acting as a tireless research assistant that can generate structured content grounded in facts.
Here are a few ways it’s being used:
- Market Analysis Reports: A financial analyst can feed a RAG system a competitor’s latest quarterly earnings reports and ask it to generate a full analysis. The system will extract key figures, identify important trends, and summarize the findings.
- Legal Document Summarization: A paralegal can upload hundreds of pages of case law and ask the RAG tool to summarize the key precedents related to a specific legal question, saving hours of reading.
- Product Descriptions: An e-commerce manager can give the RAG model a technical spec sheet for a new product and have it generate a compelling, customer-friendly product description in seconds.
In every case, RAG makes sure the generated content isn’t just well-written but is also factually anchored to the source materials you provided. This mix of retrieval and generation makes it an incredibly powerful tool for anyone whose job involves synthesizing information.
Best Practices for Implementing a RAG System
Putting a Retrieval Augmented Generation (RAG) system into action is more than just a technical project; it’s a strategic move. A powerful and reliable RAG application isn’t built on code alone. It’s the result of smart decisions made long before you start developing. Following a few key best practices will set you on the right path to a system that delivers accurate, relevant, and trustworthy answers.
And the interest in this technology is exploding for a reason.
The RAG market is growing fast, which tells you a lot about its adoption rate. According to a 2024 market report, the Retrieval Augmented Generation market was valued at around USD 1.3 billion and is expected to blast off to USD 74.5 billion by 2034. That’s a compound annual growth rate of 49.9%, with North America owning over 37.4% of the market share. You can dig into the numbers yourself in this comprehensive RAG market analysis.

Prepare and Clean Your Knowledge Sources
The performance of any RAG system comes down to the quality of its knowledge base. It’s simple: garbage in, garbage out. Your model’s answers will only ever be as good as the data you feed it. Before you even think about models or databases, your top priority has to be prepping your source documents.
This means ditching irrelevant info, fixing errors, and standardizing formats. If your knowledge base is cluttered with outdated policies, duplicate articles, or messy data, your system will pull confusing and flat-out wrong context. A clean, curated, and well-organized document set is the foundation of a high-performing RAG application.
Select the Right Embedding Models and Vector Database
Once your data is in good shape, it’s time to pick your tech stack. The embedding model turns your text into numerical vectors, and the vector database stores and searches them. Your choices here will directly affect both the accuracy and speed of your system.
- Embedding Models: Some models are built for short text snippets, while others are pros at handling long, technical documents. Think about your content. A model trained on scientific papers probably won’t do well with a database of customer service chats.
- Vector Databases: Your choice here depends on things like scalability, search speed, and how easily it plugs into your existing systems. You can find everything from managed cloud services to open-source solutions you host yourself. Weigh the trade-offs based on your team’s expertise and where you see this project going long-term.
The connection between your embedding model and vector database is absolutely vital. A top-tier model paired with a slow or clunky database will just create bottlenecks and a frustrating experience for everyone.
Develop an Effective Chunking Strategy
You can’t just dump entire documents into your system and hope for the best. Big files need to be broken down into smaller, bite-sized pieces, a process called chunking. A smart chunking strategy is necessary for making sure the retrieval process grabs the most relevant context without overwhelming the language model.
Your approach to chunking needs to fit your content. For a technical manual, you might chunk by section to keep the logical flow intact. For a bunch of Q&A articles, you might chunk each question-and-answer pair together. The idea is to create chunks that are small enough for a quick search but big enough to hold meaningful, self-contained information. You’ll likely need to experiment with different chunk sizes and overlap strategies to find what works best.
Monitor, Evaluate, and Create Feedback Loops
Launching your RAG system isn’t the finish line; it’s just the start. You have to keep monitoring and evaluating it to maintain and improve performance over time. This means setting up metrics to track the quality of its responses and creating feedback loops to spot areas that need work.
This could be as simple as tracking user satisfaction scores, seeing which documents get pulled most often, or having human reviewers score the accuracy of the answers. This data gives you priceless insights. For example, if users keep getting unhelpful answers on a certain topic, it’s a huge red flag that the source documents for that topic need an update. This cycle of refinement helps you improve everything from data quality to your chunking strategy, making sure your RAG system delivers value for the long haul.
These loops can also point out gaps in your knowledge base, which is a key part of delivering proactive customer service.
Got Questions About RAG? We’ve Got Answers.
Even after seeing how it all works, you might still be wondering how Retrieval-Augmented Generation fits into the bigger AI picture. Let’s tackle some of the most common questions to clear up any lingering confusion.
What’s the Real Difference Between RAG and Fine-Tuning?
The core difference is all about how a model gets new information.
Think of fine-tuning like sending a student to an intensive course on a new subject. They spend weeks studying, and the process actually changes their internal knowledge. The model’s core parameters are retrained on a new dataset, fundamentally altering its built-in expertise.
RAG, on the other hand, doesn’t change the student at all. It’s like giving that same student an open-book exam with a curated library of reference materials. Their core knowledge remains the same, but they can suddenly answer highly specific questions with up-to-the-minute facts. RAG is much faster and is the clear winner when you’re dealing with information that changes all the time.
Can RAG Handle Any Kind of Data?
Pretty much, yes. RAG is incredibly flexible and can work with a huge range of unstructured text data. This makes it a powerful tool for businesses sitting on mountains of information in different formats.
Here are just a few examples of data that RAG handles beautifully:
- PDFs and Word Documents: Think internal reports, dense policy manuals, and technical specs.
- Knowledge Base Articles: All that great content in your company’s support center or internal wiki.
- Web Pages and Transcripts: Content from your public website or transcribed meeting notes can be indexed and made ready for questions.
- Databases and Internal Wikis: Both structured and unstructured data locked away in company systems can become a goldmine of knowledge.
The magic happens in the prep work. You have to process this data into a format the system can search. This usually involves breaking down big documents into smaller, logical pieces (chunking) and turning them into numerical representations called embeddings. As long as your info can be indexed, it can power a RAG system.
How Exactly Does RAG Stop AI Hallucinations?
AI “hallucinations” are a huge problem. They happen when a model confidently makes things up that are just plain wrong. RAG is one of the best defenses against this because it forces the model to ground its answers in facts you’ve provided.
Here’s how it works: before generating a single word, the RAG system first fetches the most relevant snippets of information from your trusted knowledge base. This retrieved context gets bundled up with the user’s original question and sent to the LLM.
The model is essentially given a direct order: “Answer this question, but only use the facts I’m giving you right now.” By fencing the LLM in with pre-verified information, you dramatically reduce the chances of it going off-script and inventing details.
RAG shifts the LLM’s role from “all-knowing oracle” to “expert synthesizer.” It’s not creating facts from memory; it’s reasoning based on the evidence provided. This simple shift is a powerful guardrail against hallucinations.
Is RAG Too Complicated for a Small Business to Implement?
Not anymore. While building a custom retrieval augmented generation rag pipeline from the ground up can be a serious engineering project, the rise of managed services and open-source tools has changed the game completely.
Platforms like AWS Kendra or Azure AI Search handle a lot of the heavy lifting for you. For many small businesses, starting with one of these services is the most practical path forward.
Honestly, the biggest challenge often isn’t the technology, it’s the content. Your success with RAG depends almost entirely on having a clean, well-organized, and up-to-date knowledge base. It takes some planning, but getting a powerful RAG system up and running is now well within reach for smaller teams.
Ready to see how a RAG-powered chatbot can transform your customer support? Social Intents provides AI-driven live chat solutions that integrate directly with the tools your team already loves, like Microsoft Teams and Slack. Automate responses, pre-qualify leads, and provide accurate, instant answers grounded in your own knowledge base.

